
The Dawn of Artificial General Intelligence - How Language Models might have evolved into Intelligent Beings
A recent study by a Microsoft research team dived into the capabilities of GPT-4. The findings of this research are both exciting and concerning at the same time, as the team suggests that GPT-4 could be the world's first Artificial General Intelligence (AGI).
If you're interested in learning more about this groundbreaking research, I highly recommend watching Sebastien Bubeck's enlightening talk before you read on: https://youtu.be/qbIk7-JPB2c
But first, some background
In 2013, Google introduced their word2vec models, a revolutionary breakthrough in the field of natural language processing. This development allowed for the training of neural networks without the requirement of human annotators and at a considerably lower computational cost. However, the most remarkable aspect of this innovation was the simplicity of the idea behind its learning method - predicting the next word in a given text. This approach proved to be highly effective and has since paved the way for numerous advancements in AI language models.
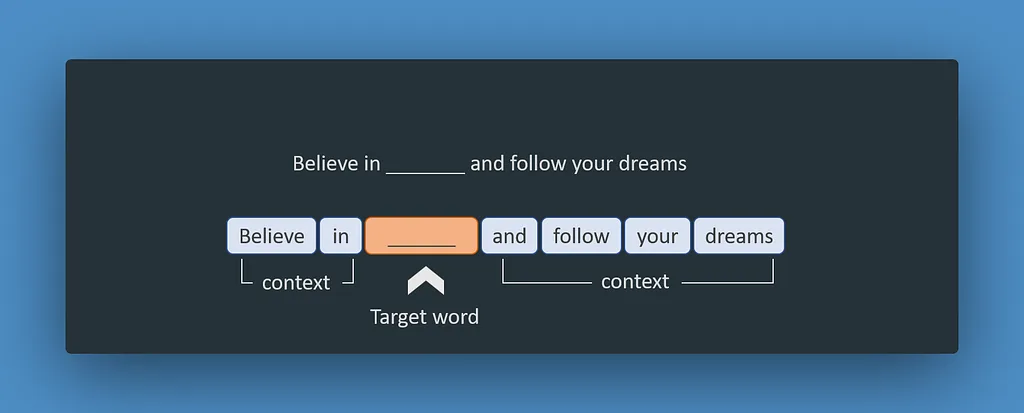
This so called unsupervised method of training, elegantly avoided the need for labeled data. Instead the neural network would predict the next word on a huge corpus of text - typically on a dump of Wikipedia - over and over again until something remarkable happened. The model was able to create an inner representation of the text that it was trained on.
The inner representation developed by these models has proven to be highly versatile. Enabling the autonomous classification of documents or spam, sentiment analysis, and basic question-and-answering tasks. It's worth noting that many of the tools we use on a daily basis heavily rely on these models to this day. But nobody - including me - at that time would have thought that this would lead to some degree of intelligence.
Fast forward to 2017, researchers at Google publish the paper "Attention Is All You Need" introducing a novel neural network architecture called the Transformer model, which outperformed all formerly known architectures in language specific tasks by a huge margin.
These new models were able to assign different weights to each word in a sentence based on how it relates to others. Words could now be understood contextually, leading to major breakthroughs in the capabilities of these models. Eventually, the transformer architecture enabled neural networks to have a deep, contextual understanding of the human natural language, which has allowed these models to distill large volumes of unstructured data into a concise summary, create more accurate translation and answering complex questions, among many others tasks.
The Race begins
Once the potential these new models became evident, a fierce arms race began between a handful of organizations, sharing the goal of pushing the limits of this architecture. The focus was solely on scaling up the layers/parameters count to create even larger language models, resulting in an intense competition among the contenders.
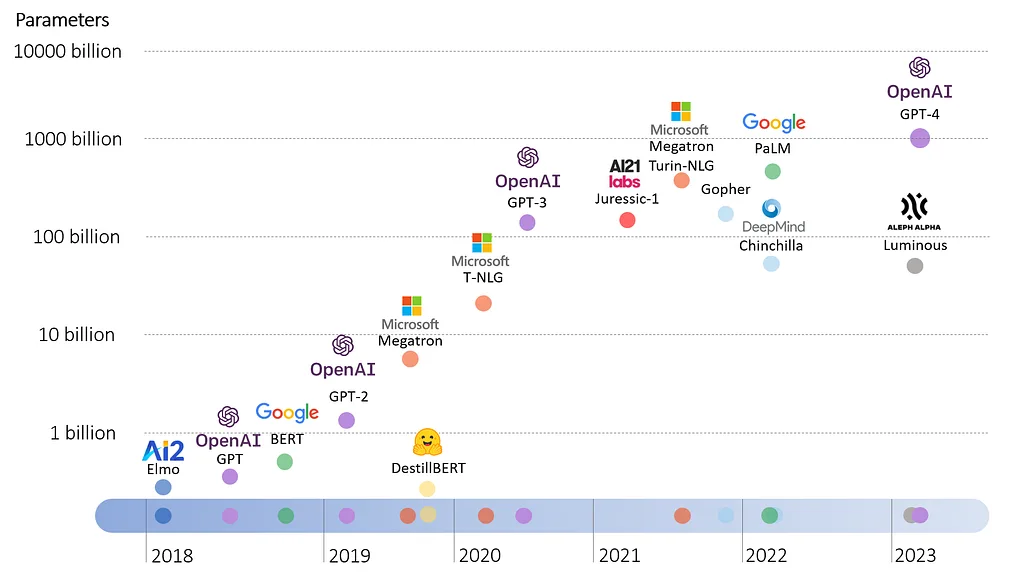
Training these huge models would get very cost-intensive. Luckily at the same time cloud hosters like AWS, Azure and GCP, integrated more efficient and more powerful compute Units into their servers, thus enabling the training of bigger models. This arms race is still progressing and recently culminated in the realese of a transformer model called GPT-4 by OpenAI, the biggest known large language model in history supected to have over 1 trillion parameters.
Ok, but what actually is intelligence?
As the research group from Microsoft wanted to answer the question if GPT-4 is an artificial general intelligence they first neededed to agree on a very general definition of what the term intelligence actually means. Gladly, in 1994 a group of 52 psychologists came up with a definition.
Intelligence is a very general mental capability that involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and to learn from experience.
The research group argues that a model that has all the stated abilities should be called an artificial general intelligence.
Inner representation of the world
To put their assumptions to the test, the authors conducted a variety of empirical experiments. Let me highlight the most mind blowing ones.
In an early experiment they asked GPT-4 to draw a unicorn in Tikz, which is a script language to draw illustrations. It was able to draw a visual representation of a unicorn despite not being trained on images. It was also able to modify the image when prompted to do so, which implies that GPT-4 has a real understanding of the complex concept of a unicorn.

They repeated this experiment on a fairly equal time interval as GPT-4 was still trained. It showed that it got even better at understanding the concept of a unicorn as it was trained for a longer period.
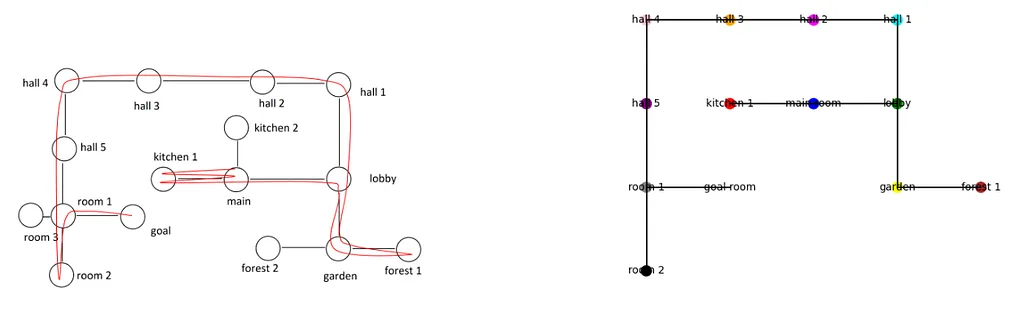
In another experiment, researchers played a text-based game where GPT-4 was tasked to explore an imaginative map consisting of different rooms through text prompts until it found the goal. They then asked it to draw the map and GPT-4 was able to accurately produce a visual representation of all the rooms it had visited. The researches also claim that this tested version of GPT-4 had only be trained on text data, which makes this result even more outstanding.
Is GPT-4 an AGI ?
The authors argue that GPT-4 has capabilities in all the mentioned dimensions but the planning dimension. Planning is something that GPT-4 is exceptionally bad at. As GPT-4 is frozen in time and is not updating its parameters it can also not learn from past experiences. Although this is more of a policy based constrained and not something the model itself is limited by.
Besides this major shortcoming of GPT-4. It exceeds at almost all other dimensions. Thus, the group of researchers argue that GPT-4 should be called an artificial general intelligence. It might not be the most sophisticated AGI but based on their definition it should be called the first one to be created.
As exciting as the introduction of GPT-4 is, this is still just a snapshot in time. You can assume that other organizations are currently training even more capable models.
What is also clear is that there is a lot of room for improvement let alone by improving the transformer architecture. As these organizations have thrown massive amounts of compute and data to get to this level, I suspect that the next big leap will come from a change in the architecture of these models.
What does that mean for the future?
Surprisingly it seems that the key to unlock intelligence is purely dependent on the sheer number of somewhat connected dynamic parameters. As we reach models with more than 10 trillion parameters or more we have to expect that these models will eventually become more intelligent than any human ever lived. At the current speed of development, the AI industry is clearly outpacing academia as we still don't actually understand how these models "think" and why these capabilities emerge.
As scary as it sounds, but it looks like sophisticated AGI's are not as far away as a lot of experts in the field have suspected.
This also means that there is a realistic threat of an uncontrolled AGI that can potentially harm all of humanity. It will take a lot of careful consideration and guiding rules to harness the positive impact that these models will have and at the same time mitigate the negative aspects as much as possible.